
Ian Main
Ian is a Distinguished Technologist at HP Teradici. Ian has over 15 years of experience at HP Teradici, involved in protocol performance, architectural and security aspects of PCoIP design, and customer requirements analysis, with particular focus on remote graphics intensive workflows. Follow Ian on Twitter! https://twitter.com/PCoIP_Ian
This is the sixth post in a technical blog series by Ian Main, Teradici's Technical Marketing Principal. In the series, he'll go through the PCoIP Ultra protocol enhancements from a technical perspective, and answer common questions that have come up since the release of the enhancements.
And now without further delay, over to Ian!
PCoIP UltraTM Technical Series Part 6: PCoIP Ultra Efficiency – Especially for GPU Offload
Now that we’ve explored aspects of PCoIP Ultra architecture, client compatibility, CPU scalability, and network bandwidth considerations, let’s look at overall CPU efficiencies to be gained.
Here are two scenarios:
- When AVX2 enhancements are leveraged
- When NVIDIA vDWS environments have the NVENC GPU offload engaged
For this benchmark, I used my original 8-core R7910 infrastructure loaded with a 1080p 60 fps version of the Big Buck Bunny video workload which may be somewhat characteristic of an animation studio environment. The graph shown plots the percentage of CPU consumed for 2 core (2 pCPU) through to 8 core (8 pCPU) server configurations. The CPU utilization shown is the gross consumption including contributions from both VLC video player application and PCoIP Server process.
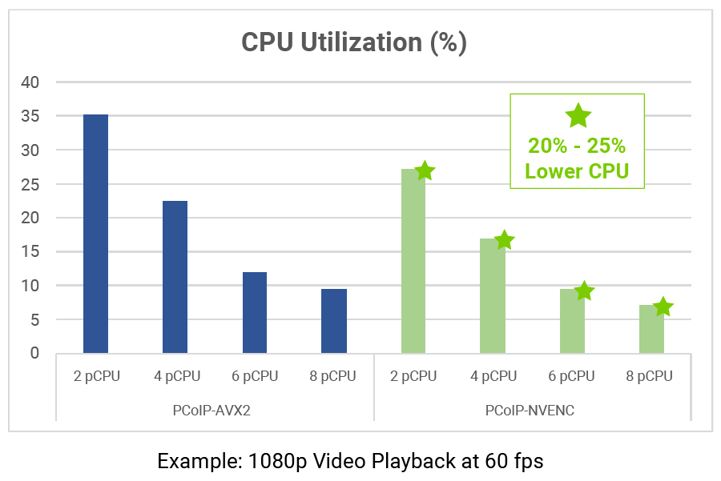
As you see on the right, one immediately picks up on significant savings to be gained using PCoIP-NVENC offload for the smaller server configurations. It’s more than 20% savings over AVX2 which may count significantly during capacity planning. While not shown in the graph above, SSE4.2 weighs in at 47% for the 2-core pCPU case so Ultra-AVX2 shows good benefit (12% savings) in the case of AVX2 acceleration over SSE4.2 too. For the 8-core server, savings are slightly more modest, but have a positive consolidation benefit for multi-user vGPU environments regardless.
For existing Teradici PCoIP Remote Workstation Card users, the fact that the 8-core platform yields less than 10% load in both cases for this exemplary benchmark, beckons compelling Cloud Access Software alternatives when the next hardware refresh cycle rolls around.
In the final post, we’ll investigate image quality settings for PCoIP Ultra. With an enhanced continuous quality dial all the way up to Q100, the sky is literally the limit.
For a deep dive into PCoIP Ultra, check out this webinar:
In case you missed it:
Part 1: Top-Level Architecture
Part 2: PCoIP Ultra Client Capability
Part 3: Four Times the Pixel Rate
Part 4: PCoIP Ultra Efficient CPU Scaling
Part 5: What About Bandwidth Consumption?
Ian Main
Ian is a Distinguished Technologist at HP Teradici. Ian has over 15 years of experience at HP Teradici, involved in protocol performance, architectural and security aspects of PCoIP design, and customer requirements analysis, with particular focus on remote graphics intensive workflows. Follow Ian on Twitter! https://twitter.com/PCoIP_Ian