
Ian Main
Ian is a Distinguished Technologist at HP Teradici. Ian has over 15 years of experience at HP Teradici, involved in protocol performance, architectural and security aspects of PCoIP design, and customer requirements analysis, with particular focus on remote graphics intensive workflows. Follow Ian on Twitter! https://twitter.com/PCoIP_Ian
This is the fourth post in a technical blog series by Ian Main, Teradici's Technical Marketing Principal. In the series, he'll go through the PCoIP Ultra protocol enhancements from a technical perspective, and answer common questions that have come up since the release of the enhancements.
And now without further delay, over to Ian!
PCoIP UltraTM Technical Series Part 4: PCoIP Ultra Efficient CPU Scaling
The previous post introduced the tremendous throughput gains using NVIDIA NVENC GPU offload or taking advantage of AVX2 optimizations. Today, we’ll explain why the AVX2 processor should be thought of as a scalable acceleration unit and how the benefit scales with additional core count.
As a quick side, AVX2 processor extensions are available in most modern servers and workstations – these special registers and instructions enabled some Teradici boffins to pack and process sets of 16 pixels concurrently, on each available core! Previously such gains would have required dedicated silicon co-processors, akin to our original TERA processors. Of course, hand coding the critical areas of the encoder was a significant project, but well worth the effort.
Take a look at the sketch below – even a sluggish ~2 GHz processor with 16 cores is capable of 16 cores x 16 pixels per operation x ~2 operations per cycle x 2 GHz which approaches 1 tera-operations-per-second. Remarkable!
![]()
This brings us to another marketing slide from our PCoIP Ultra launch campaign which, at least conceptually, shows the relationship between encoder design and throughput:

Left: We show our original SSE2 encoder which is available in VMware Horizon. This single-threaded implementation is well suited to VDI workloads which demands high image quality but not generally high pixel throughput.
Center: Teradici Cloud Access Software improved on the throughput with the SSE4.2 implementation, which includes multi-threading support up to approximately 8 threads, beyond which efficiency is diminished.
Right: The PCoIP Ultra AVX2 enhancements are shown. Assuming 16 processor cores shown, the encoder leverages all available AVX2 engines which provides dual benefits of distributing the encoding workload and maximizing the CPU availability to application software. In other words, the PCoIP-AVX2 encoder operates as a thin layer between operating system and application. The more cores available, the lower the impact on your application.
At the processing detail level, we divide each image frame into multiple small tiles of pixels which allows us to use all the AVX2 engines of a multi-core CPU in a concurrent fashion. Each free AVX2 engine is assigned a tile, processes it quickly and immediately assigns another tile which accelerates overall throughput. We add some processing wizardry to prevent image discontinuities known as blocking artifacts along tile boundaries – a common problem with tile-based image processors.
To illustrate AVX2 CPU scaling…
I ran a handful of PCoIP Ultra benchmarks on a dual processor 3.5 GHz Xeon server (8 physical cores) at different core counts (pCPU) – comparing looped playback of the opening scene of Big Buck Bunny (24 fps version) at native 1080p to playback at full-screen 4K/UHD:
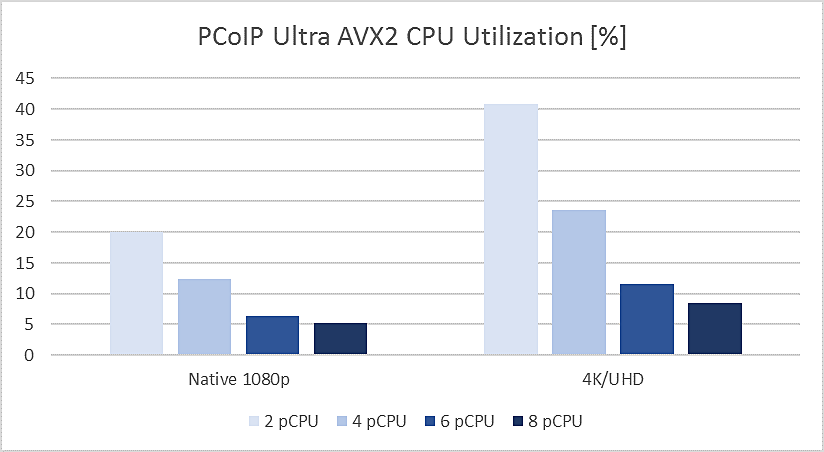
For the 4K/UHD workload on the right, a dual core workstation comfortably handles 30 fps video playback but consumes 40% of the CPU, including both VLC Player and PCoIP Agent processes. CPU drops nicely as cores are added to less than 10% when 8 cores are deployed.
For the 1080p workload on the left, a tidy 5% of CPU resources are required using 8 cores. Bearing in mind that these tests were conducted on a mid-life 8 core machine and that Xeon processors about to surpass 50 cores, I see a very low impact encoding future ahead!
Next post:
Stay tuned for a CPU and bandwidth comparison between PCoIP Ultra and the SSE4.2 implementation.
In case you missed it:
Part 1: Top-Level Architecture
Part 2: PCoIP Ultra Client Capability
Part 3: Four Times the Pixel Rate
Ian Main
Ian is a Distinguished Technologist at HP Teradici. Ian has over 15 years of experience at HP Teradici, involved in protocol performance, architectural and security aspects of PCoIP design, and customer requirements analysis, with particular focus on remote graphics intensive workflows. Follow Ian on Twitter! https://twitter.com/PCoIP_Ian